广州华立科技职业学院 广东省广州市 511300
摘要:目前,嵌入式处理器已广泛地应用于航空航天、显示处理、工业控制等诸多领域。汽车发动机控制,门窗控制,家电控制,电动汽车和电动汽车,电动汽车和电动汽车。目前,嵌入式处理器已广泛地应用于航空航天、显示处理、工业控制等诸多领域。汽车发动机控制,门窗控制,家电控制,电动汽车和电动汽车,电动汽车和电动汽车。
最近几年 ARM公司研制出了一种基于简化的指令集结构的嵌入式处理器,它被广泛地应用于各种类型的嵌入式处理器。同时,支持RISC-V的开放源码简化指令系统结构的嵌入式处理器内核也在不断涌现。随着外部设备数目的增加,嵌入式处理器核心与 DMA (DMA)、外部设备、外部设备间的通信量也在不断增加。这就增加了总线的吞吐量和存取时延。在嵌入式系统和外部设备之间,采用单一或多层 AHB总线,且仅有一台主机与外部设备进行通讯,从而影响了系统的工作效率。本文通过对嵌入式处理器核心体系结构特性的分析,并根据其应用要求,给出了一种基于 MCU的总线结构,并对其进行了模拟与验证。
关键词:微控制器;片上系统;内核设计
MCU是目前最常用的 IC之一,而八位 MCU则是最具性价比的一种。MCU的核心部分主要是 CORE,通过内核的设计,通过外部资源的辅助,可以实现真正的应用。随着 MCU在整机市场上的需求在不断的改变,因此,如何设计出一款适合于不同应用核心的产品,而又不会受到工艺环境的制约。本论文主要研究一种八位 MCU的核心性能,通过逻辑综合,实现了一种通用的内核;也就是用top-down的设计方法,进行core-based的设计,以形成所需要的产品.基于这一点,我们可以根据用户的需求,开发出不同的产品。
1八位MCUCORE的结构及各部分功能
文中给出了8比特 MCUCORE的结构。在图1中, ALU是一个算术逻辑操作装置;A- Reg是累积的寄存器;X-Reg是一个地址转换的寄存器, PC是一个程序的计数, SP是一个栈的指示器;CCR是一个有条件代码的寄存器;MOPGEN是一种微型运算发生装置,由指令寄存器、指令周期状态机、微运算编码电路组成;MOP是一个微型的界面装置;INTERUPT是内部和外部中断模块;CLOCK是一个时钟发生装置;RESET是一个重置的模块。
1.1算术逻辑运算单元ALU
ALU为CORE的核心单元之一,是一个8位的算术逻辑运算单元,它完成所有的逻辑和算术运算。

图18bitMCUCORE的结构示意图
1.2累加寄存器
A-Reg和可变址寄存器X-Reg累加寄存器和变址寄存器都是8比特的寄存器,当进行算术或数据处理操作时,存储第一个操作数和结果,而地址寄存器主要是变址寻址,它包括8比特数值,可以与0,8或16比特的即时数相乘,从而生成一个有效的地址。
1.3程序计数器PC和堆栈指针SP
程序计数器 PC是一个16比特的寄存器,其最高3比特总是0,它含有下一条指令要被执行的地址;栈指标 SP是一个13比特的寄存器,该寄存器中的下一个闲置单位地址,实际的栈是6比特,7比特高的7比特总是0000011。
1.4条件码寄存器CCR
CCR也可以称为程序状态字(PSW),具有5个比特,在该比特中,一个半进位 H,一个负标志位 N,零标志位 Z和一个进位/借位标志位 C,表示一个刚刚完成的命令的结果,一个 I位用来禁止/准许一个中断。可以通过程序单独地对这些状态比特进行测试,并根据其状态进行规定的操作。CCR是一种8比特的寄存器,其高3比特总是1。
1.5微操作产生单元
MOPGENMOPGEN是 CORE的一个重要组成部分,它的功能是:从内部的数据总线中选取输入的数据;基于命令的种类来决定命令的时间间隔;按照要求完成任务发出指令,在每个节拍中对 ALU和内部寄存器进行微操,图2显示了它的内部数据流。DB是 CPU中的一条数据总线,其上的数据包括了指令和运算。
指令寄存器在先导脉冲的控制下,从数据总线中提取指令,生成16比特的数据;16比特数据一方面进入指令循环状态机,生成一套10比特的状态数据,而另一部分则随着状态数据进入微操作编码器,生成67个微操作,用于对 ALU的操作和内部寄存器进行数据流的控制。命令周期状态机输出确定的命令执行时段,完成命令后生成先导脉冲,解控制命令寄存器从 CPU的数据总线中选取下一条指令。
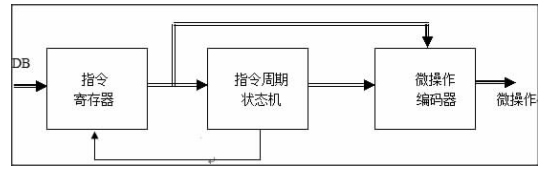
图2MOPGEN中的数据流
1.6微操作接口单元
MOP从MOPGEN产生的67个微操作在控制ALU的运算及内部数据流之前先要经过MOP这一模块,在CPU主时钟的作用下,该模块产生以下几类控制信号:基本运算方式及运算结果控制信号;移位及负操作控制信号;内部数据总线与外部数据总线之间的数据交换控制信号;程序计数器控制信号;堆栈指针控制信号。
1.7内部、外部中断模块INTERRUPT
INTERRUPT模块主要实现了外部中断、定时器中断、 SCI中断和 SPI中断等功能;一个中断矢量,它会生成上述的中断;在低功率模式下生成 STOP和 WAIT控制信号。
1.8时钟产生单元
CLOCK外接晶振在经过时钟生成单元的除法等的处理之后,生成如下的时钟: CPU的主时钟;定时器, SCI串行通讯接口, SPI串行外部接口;CPU,输入/输出端口, ROM, RAM时钟;定时器,串行通讯接口 SCI,串行外部接口 SPI时钟, SCI, CPU时钟, I/O外部扩展时钟。
1.9复位模块
RESET复位模块的功能:外部复位信号及电路内部上电清零信号,经过与CPU时钟之间的逻辑组合产生CORE的复位信号。
2指令在MCUCORE中的执行
本论文所设计的8位 MCU共210条指令,全部采用 CORE MCU核心。在 MCUCORE、 ROM、 RAM等构成的结构中,执行指令的调试,见图3;在指令的调试阶段,编制了210个指令,并尽量兼顾不同的应用情况;此外,在调试期间还进行了上电复位、外部重置脚复位以及多种中断要求。
图3指令调试结构示意图
以下用带进和指令表示指令的执行,它有六个地址模式,其指令形式、操作代码、完成操作、执行周期和指令效果的条件代码等。
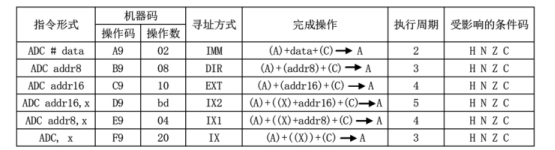
表1带进位加指令
3MCUCORE的应用
MCUCORE由 CPU、时钟、 RESET、内部和外部的干扰请求组成,组成一个完整的微处理芯片,再加上存储器、定时器、 SCI、 SPI、 I/O端口,组成一个完整的微处理芯片。

图4MCUCORE的配置举例
4总线系统设计
总线子系统的设计是针对多层 AHB总线系统所面临的问题进行分析,其目的在于解决多个主机对不同外部设备的需求,而设置两层 AHB总线则会造成系统的访问时延。由于每一层总线都要经过总线的分割和仲裁。因此,在提高总线效率的同时,也要考虑到总线系统的可重用性。该系统中使用了多个 AHB总线和多个总线中心组成的总线阵。
4.1总线架构
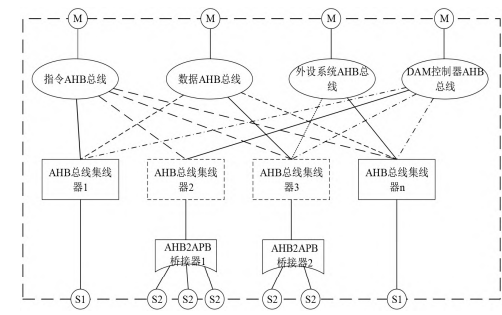
AHB总线采用AHB-Lite总线的架构.AHB-Lite是 AHB总线系统的一个子集,它是一种 AHB总线的结构,AHB-Lite中只有一个主机(Master),不存在总线竞争,因此无需 HGRANTx和 HBUSREQx作为仲裁的两个信号,从而避免了总线仲裁过程。同时,还可以省略总线锁定信号。在图5中显示了总线体系结构。
图5总线系统架构
在总线存取过程中,可以节约总线和授权验证的时间。当多个总线主机对同一总线的存取进行仲裁时,将其交给 AHB总线中心。在不同的总线主机接入不同的从属设备时,由于 AHB总线的控制不能被控制,将不会发生发送延迟。从各个主控制器的角度看,所有从机都是独立的,没有任何的存取冲突。
2.2AHB-Lite总线
在AHB-Lite总线中,省略了仲裁处理模块,各控制器分别对AHB-Lite总线进行控制,并在开始一次发送时,对所述控制和所述数据信号进行登记,并在解码器的控制下向相应的从属装置传送。因为从机与主机共用,所以从机的地址空间是连续的和惟一的,以便于软件的开发和避免地址冲突。对于同一从装置,每个AHB-Lite总线的编码表都是一样的[3、6]。
2.3总线集线器
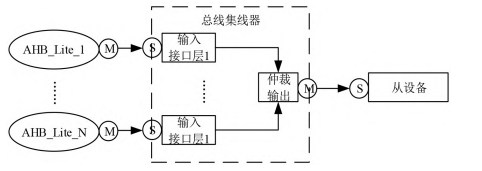
总线集线器是在同一个从设备有多个主控器进行访问时,将各个主设备通过连接到一起通过一个从设备访问接口连接对应的从设备[4]。如果不同的主控器需要访问同一个从设备时,从设备可以通知主控器是否正在工作。为了避免请求丢失,需要存储来自主控器的地址和控制数据和相关的地址解码结果。当其他主控器完成传输后,可以将存储的主控器请求传递给从设备。无法获得从设备访问权限的主控器,其hready_resp将被设置为低,只到允许访问后,hreadyresp才会变高[5]。总线集线器结构如图4所示。
图6总线集线器结构
总线中心根据不同的应用程序,分别采用固定优先权和动态优先权。在一个固定的优先权仲裁机制中,每一个主机都有一个独特的优先权。仲裁程序根据优先权,从不同的主机中选取一个发送。若从装置支援 burst传送,仲裁选项仅在 htrans为 IDLE或NON-SEQUENTIAL时才会被更新以避免中断 burst传送。如果从机不支援 Burst传送,那么每一次传送都会进行一个优先权判定。在动态优先权仲裁机制中,使用了 RoundRobin (RoundRobin)算法。当复位结束时,所有的主机都会被赋予初始的优先权,但当一个主机拥有从机的权限时,其优先权就会降到最低,这意味着每一台主机的优先权都不会被固定,而是会在拥有从机的权限后,将相邻的主机的优先权设置为最高,并对其它主机进行一次调整。
算法执行过程如表2:
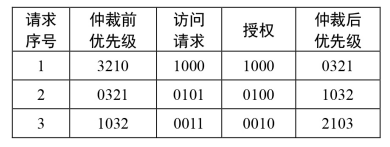
表2轮询调度算法演示
这里有4个主机要求存取从机,3代表最高的优先权。第1次,3号主控制器被允许访问,3号主控制器的优先级被降低到0,其余的主控制器被调成0321,3号主控制器右侧的2号被调到了最高3。第2次,2号主机被允许访问,2号主机的优先级被降低到0,其余的主机被重新设置到1032。第3次,1号主机被允许访问,1号主机的优先级被降低到0,其余的主机被设置为2103。为了存入 Flash存储器模块,既要存取核心指令和数据,也要存取指令总线及数据总线,但仅当命令被执行至取得数据指示时,数据总线才被存取,所以,命令总线及数据总线存取 Flash的总线中心被设定为一个固定的优先权仲裁。由于大部分的外部设备都支持多个主机存取,因此,为了平衡存取的负载,大部分都是以动态的优先权仲裁机制来实现的。
3仿真测试
3.1前端仿真验证

在 MCU芯片项目中,利用 Verilog语言进行了 MCU总线的设计与实现。最后,利用新思公司 VCS系统对其进行了前端验证。图7为三个主机存取一个存储器,从装置0x2100004起一段数据。其中,主指令的优先权比数据和 DMA的优先权要高。命令主机获取总线存取权限,并执行存取操作。
图7仿真波形
3.2FPGA原型验证

为了验证设计整体的功能与性能,在仿真测试的基础上搭建了原型验证平台,采用了Altera公司CycloneIV系列的FPGA芯片进行了原型验证[7]。如图8所示。
图8FPGA原型验证平台
3.3流片验证

利用所设计的 MCU总线结构,研制出一款以110 nm Flash为核心的 MCU芯片,经封装后,总线主频可达120 MHz,各项性能指标均满足指标要求。图9中显示了 MCU裸芯片,该芯片具有大约20mm2的面积。
图9MCU裸芯片
4结论
本文采用 Verilog语言对 MCU进行了性能描述,并将其应用于210条指令中,验证了 CORE的性能,并在此基础上加入了内存和周边器件,从而构成了一个8比特的单片机。经过这一课题的研究,我们已经初步了解了一种八位 CPUCORE的工作原理及core-based的设计要点。
参考文献:
[1]董巍,谢憬,毛志刚.多层次AHB总线架构中BusMatrix的设计和实现[J].现代电子技术,2009:132-135
[2]李璐,汤跃科,陈杰.基于CrossbarSwitch结构的多层AMBA高速总线的设计及其应用[J].电子器件,2007:372-375+379
[3]王一楠,林涛,余宁梅.基于AMBA的AHB总线矩阵设计[J].微电子学与计算机,2019,36(2):5
[4]罗惠文,吴斌,尉志伟,叶甜春.AHBMatrix互连总线IP的设计与实现[J].微电子学与计算机,2015:60-63
[5]陈虎,董会宁,范逵,董健.基于InterconnectMatrix结构的多层AHB总线设计与实现[J].通信技术,2009:218-221
[6]ARMLimited.AMBATMSpeciicationRev2.0.ARM[S].British,Cambridge:ARMLimited,1999
[7]刘云晶,刘梦影.一种32位MCU的FPGA验证平台[J].电子与封装,2020:41-47
[9]RaviM.DesigningofaAMBA-AHBMultilayerBusmatrixSelfMotivatedArbitrationscheme[J].IOSRJournalofElectronicsandCommunicationEngineering,2013(1)
[10]居水荣.一种带LCD驱动的8位微控制器[J].半导体技术,2002,27(7):53-58
.[11]居水荣,刘锡锋.基于嵌入式MCU的音频芯片信号处理模式[J].科技创新与应用,2014(1):7-9.
[12]朱建卫,居水荣.一种可嵌入MCU的8位高速乘法器的设计[J].微电子学,2010,40(6):832-835.

客服QQ:30444492琼网文【2021】1550-113号
增值电信业务经营许可证:琼B2-20210322
出版物经营许可证:新出发龙华出字第(2021)009号
广播电视节目制作经营许可证:(琼)字第00779号
版权所有 ©2002-2024 期刊网(www.qikanchina.com) 琼ICP备2021005105号



